JavaScript & SEO – A New Perspective

Lately, a lot has been said about the influence of JavaScript on the website position in the SERPs. Even though Google robots have made visible progress in processing this type of page, their performance still leaves much to be desired. Recently, we’ve learned some new information about the topic. Want to know more? Keep reading!
Why Would You Need JavaScript on Your Website?
JavaScript is a programming language that equips a website with new functionalities. It is possible to use other languages, but it’s more difficult and sometimes impossible to get the same results.
Thanks to JS, we can create dynamic, modern websites attractive to users based on a template created in HTML and CSS.
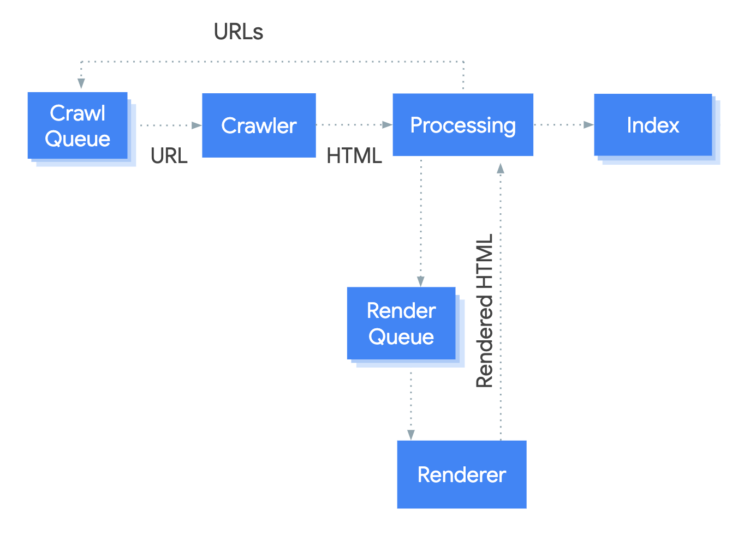
Google, however, was skeptical about this technology because its robots could not analyze the JS page the same way as others. To understand this better, let’s take a look at how Google processes JS code.
The way Googlebot has to go through is more complicated compared to less dynamic websites. To analyze such a page, robots need to download CSS and JS code, which is necessary to render the page. It makes the whole process longer and does not guarantee 100% success because of the limited crawl budget.
We can see that the level of indexed pages based largely on JS is growing year by year. Although, the rendering might still be an issue.
What Have We Learned About JavaScript from Google?
Recently, well-known Google SEO spokesman, John Mueller, spoke about the use of JavaScript.
When asked about how Googlebot approaches pages that are not user-friendly without JS enabled, he replied that reasonable use of this programming language should not have a bad effect on the SEO:
I would assume if you’re using JavaScript in a reasonable way, if you’re not doing anything special to block the JavaScript on your pages, then probably it will just work.
At the same time, he recommends testing the website (e.g. using Google Search Console, which is able to provide information about whether Google is able to index our pages and images).
Mueller recommended taking care of the technical aspects of the website – to make sure that Googlebot can see the content and links on the pages. Also, the UX aspects, i.e. the user-friendliness of the website need to be accounted for – it can be reduced by incorrect use of JS.
The latter may not be as easy to check with tools. That’s why Mueller recommends research – interviews or surveys – it will provide reliable data on this topic.
Hopefully, the influence of JavaScript on SEO is now more understandable. If you would like to develop the technical aspects of your website contact our specialist!


