Content Duplication. How to Deal With This Issue?

Content duplication is one hell of a nightmare for SEO specialists and the industry in general. It’s obvious that we should care about creating unique content, but are our efforts sufficient to do so? How does content duplicating work in practice? Do we have an impact on it in each and every case? How to check if our pieces of content get duplicated and what to do if it happens? Let’s check it out!
What is content duplication?
Long story short: content duplication is a situation where the same text appears on a few different websites or in a few different places on one website. Content duplication is usually regarded as copying content from someone else, but it is not the only source.
We can divide content duplication into two types: external and internal.
The first type – external – will appear away from our site (as the same piece of content in several places with links to our website). The second type – appears on our site (for example, identical article on many subpages). The internal type is the one that is often forgotten by e-commerce entrepreneurs, who usually blow their own trumpets regarding so-called “unique” descriptions. Unfortunately, they seem to forget about not adding the same description to a few products (or even to a few tabs, for example different colours of the same shirt).
For both internal and external duplication, copying content is caused by an intentional action or by neglecting some technical issues. It doesn’t matter what the reasons were – the truth is that it will make search engine positioning difficult and the website less visible in Google.
Google’s algorithm, called Panda and released in February 2011 (Polish search results were not analysed until August 2011, however), will definitely recognize content duplication. The main goal of this algorithm is positioning sites with unique and valuable content much higher in Google search results.
If for some reason your website will be lacking of valuable content or will have a lot of duplicated articles, even if you didn’t want them, then Google may regard your actions as intentional manipulation of the website’s search position and consider your activity as trying to cheat end users. Google could then introduce some changes in indexing and the website’s position in search results. In the worst case scenario, as site can be completely removed from search results.
What are the reasons for duplicating content?
Google states that usually, content duplication is not done with any intentions of cheating. It rather originates from some oversights or lack of knowledge. Let’s see what the reasons for duplicating content are.
Reasons for external content duplication
So-called clones of a website appear when content is copied by other websites, or when we copy content directly from them. It also takes place when, on platforms like Amazon or Idealo, we put exactly the same description of products as on our own website. Another example of such practice is to put the same information about a company in paid categories as on the website that we link to, or if we publish an article somewhere as a guest post and then we repeat it on our site (or vice versa). A common practice is to put the same description of a company as is already written on their own website. This activity increases external content duplication.
If you run a shop based on dropshipping and take some information directly from other websites, or you are a manufacturer of a particular product and those buying it from you copy your descriptions, then you should restrict content.
It’s not uncommon for sellers to copy descriptions straight from websites like Wikipedia. It makes no sense, because such websites usually have really high parameters and therefore they will be ranked and seen higher then those websites that copied content. It doesn’t come as a surprise that Google wants to show users content that’s best suited for them as well as unique. We won’t achieve much if our text is copied.

These are basically the sources of external duplication. What is the internal like?
Reasoning behind internal content duplication
1. Identical texts in category and product descriptions
Identical category and product descriptions are a real problem in e-commerce. This is the most difficult problem to eliminate. Everything described below can be solved with less work through technical optimisation.
With tens or hundreds of similar products it’s hard to come up with unique descriptions for each individual subject, especially if it has extra tabs.
Duplication is also caused by filtering, sorting and parameterising, basic in e-commerce, and blocks of the same content on subsequent subpages (regulations, footer with content).
2. The main page is available under several addresses
If our home page is available under several different addresses, this may be one of the reasons for duplicating content. This will happen if the addresses are in the same place as:
http://www.website-address.com
http://website-address.com
http://www.website-address.com/index.html or
http://website-address.com/index.html
Solution: Correct redirect between particular versions.
3. Wrong redirect after adding SSL certificate
If the website will be inappropriately redirected from http to https while implementing SSL certificate, you can expect that search engines will see two pages with the same content.
Solution? Do it wisely with SSL certificate. How to avoid some common mistakes related to SSL certificate? We covered some good practices here: SSL Certificate Installation – The Most Common Errors.
4. Wrong language versions
Another reason for duplication may be incorrect language versions of the site. This happens when the site is not completely translated and, for example, on its foreign language version, we have texts in the appropriate language, but the product names are still in first language. It’s also a bad idea to translate the text using Google Translator and paste it into a foreign language version of the page.
Solution: A separate, correctly translated text for each language version.
5. Duplicated title and meta decription tags
It’s common that a site has duplicate meta tags, which can also be negatively treated by Google. It also happens when we do not introduce various title tags and different meta description tags on a page with many subpages. In order for browser robots to interpret the page well, the title elements must be different for each subpage. Meta descriptions are less important, but when they’re duplicated, they weaken the position of the page. It is also worth introducing them manually.
Solution: the correct meta tags. We have already written about all of them here:: Meta Tags – What Are They and How do They Affect SEO?
6. Unoptimised pagination
Another problem is pagination. This is a concept in the field of printing and book production in general, but it’s also borrowed in WWW. It means paging, or shredding content into pieces and placing them on subsequent subpages. It’s used just like in books – to help the user read and browse, but also to help them index. Examples can be the results of product filtering and their several-page lists. If the same description and title tags, identical text and products will appear on each subpage, cloning will occur again.
Solution: Separate tag descriptions, titles, new text and other products on each subpage, or appropriate tagging of subpages in code and in Google Search Console.

How to detect content duplication
We already know how to duplicate content. Time to tell how to track it down. We can do it with the use of tools such as:
- Ahrefs – thanks to this you can check for internal duplication
Internal duplication analysis results in Ahrefs (site without duplication)
- Screaming Frog – it will track duplicate subpages, meta tags, as well as headings.
Analysis results of a site without duplication in Screaming Frog
- Sitebulb – also finds duplicate subpages
- Siteliner – checks for internal duplication
- Copyscape – here you can find external duplication
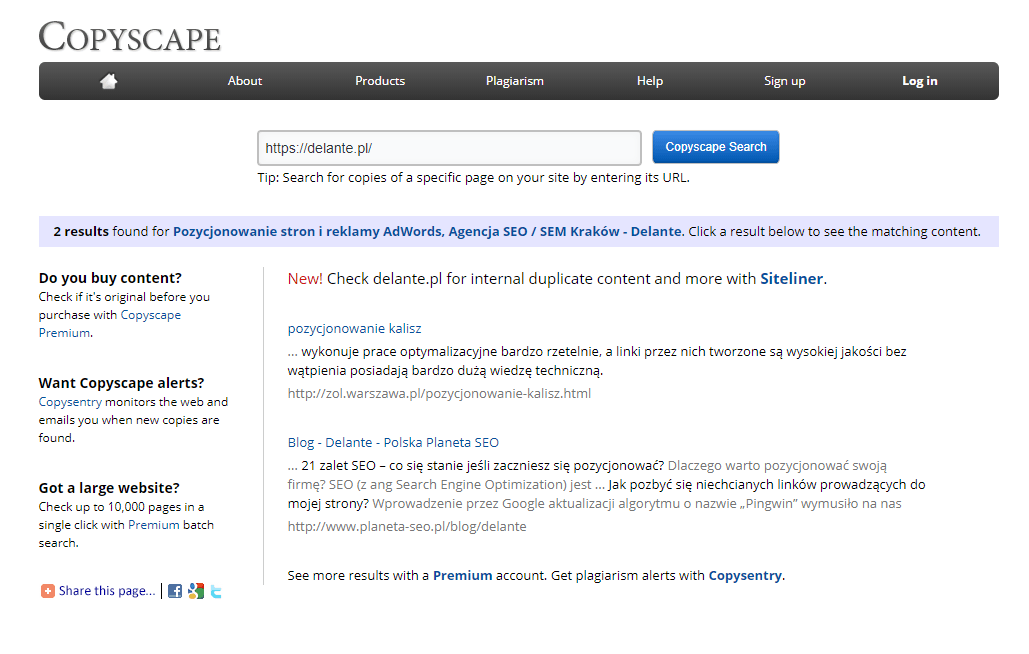 and…
and…
- ordinary Google, into which we paste a fragment of the text and check if it can be found elsewhere
Duplicate content – how to get rid of it?
Creating some unique content is not always sufficient. We also don’t have an impact on every single factor (one of the examples is aforementioned mutual content copying between various websites). What can we do to exclude duplicating information?
If a few links lead to the main page, you should correct the script and introduce 301 redirect (which means linking to a different website – to that one we want to regard as the most important ones within all existing versions of a main page). If you want to sort out the isse
In a similar way you can sort out a problem with versions with or without SSL. You can set up a preferred domain in Google Search Console.
You can get rid of headlines’ and meta tags’ duplication if you manually apply unique ones on each possible subpage.
To remove content duplication in some products’ categories, their descriptions and other tabs where they appear on, you can make the most of two solutions: either create unique descriptions or introduce canonical parameter. How to use it? We covered it here: rel = canonical. What are Canonical URLs for?
For troublesome languages’ versions the solution will be a correct implementation of hreflang parametres. How to do it right? Read here: Foreign Market Entry Success – With New Domains or Language Versions?
To finally sort out all problems with copying as for page numbering, it is essential to introduce canonical parameter, same as in aforementioned categories.
What about sorting? You can oversee another subpage for it and blocking search results’ indexing, sorting and filtering in robots.txt.
In turn, duplication in external services, where we individually post content like Allegro, Ceneo or social media, can be eliminated. All you need to do is prepare separate, unique texts. In order to avoid copying of our content by competitors, it is worth using canonical links again, and the date of publication should be included on the website and in the scheme.
Summary
To sum all our conclusions up, we should mention that not everyone regards content duplication as a bad practice. Even Ahrefs points it out in their article Duplicate Content Is A Myth. However, it’s always great to take care about the uniqueness and authenticity of content to raise users’ trust.


